
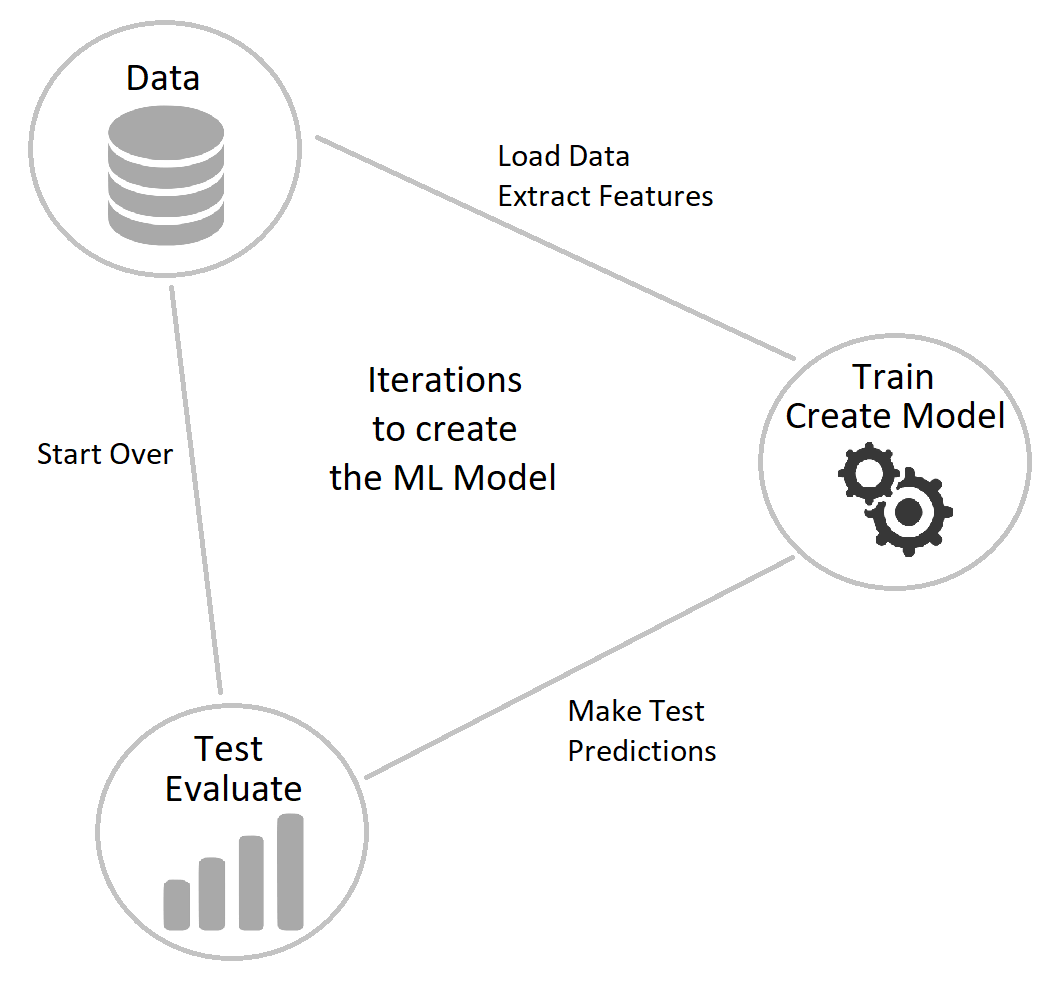
This is one of the most important images in this tutorial series. It represents the ML.NET Pipeline or more general the Machine Learning pipeline.
Previous Post: Introduction to Machine Learning in C# with ML.NET
Next Post: How to load data in ML.NET
Model Builder: How to use ML.NET Model Builder for Image Classification
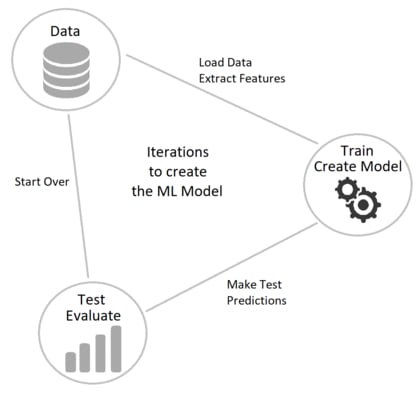
So, you have your data, then you load the data and extract features. Next, you train the model, and evaluate to see how good it is. When you are happy with the results, you can serialize the model and deploy it.
This loop happens on a development machine, be that on your laptop or on the cloud. The serialized model then can be deployed to your user application. And you can use the model in desktop applications, web application, container or microservice. The model can be used to make new prediction based on the user input.
To sum up, there are two different areas to the process. Model Creation and Model Consumption.
To create the model, you can use Visual Studio, Jupyter Notebook or any tool that can support the .NET development framework. To consume the model, you only need ML.NET and .NET Framework.
Machine Learning Model Creation
The Model Creation process is displayed in the ML.NET Pipeline image above. We simply start by gathering data. Then we need to analyze and process it. This is a very important step, and we will discuss it in more detail. But for now, it is enough to know that is part of the Model Creation process. Next, we can select the Machine Learning task that best fit our model. And finally train it.
After training, there is one more step before deploying the model, and that is evaluation. The model must be evaluated before being deployed. The output of the evaluation will show us how well the model performs. There are two options. Either we are happy with the results and move on to the next step, or we may want to tweak the process to get better results. At the very end, the model is saved and serialized in a .zip file. This is the file we will deploy on our client side.
Machine Learning Model Consumption
Having gone through the process of Model Creation we are ready to use our model. Usually, the model is saved and serialized as a zip file. On the client side, we need to load up the file, and simply use it. Model Consumption is easy. Simply get a new data point from the user, transform it, and pass it through the Machine Learning prediction engine.
ML.NET Pipeline
We have already mentioned before that the goal of Machine Learning is to take some raw data points and map them as close as possible to their set of outputs. Nothing more. This means that on the left side of the ML.NET pipeline (the beginning) data is provided. On the right side of the pipeline (the end) a prediction or classification is produced.
Depending on the task at hand, a different pipeline might be needed. But the core process is always the same. Because of this ML.NET provides us with interfaces to make the creating of the pipeline easier.
MLContext
Every single machine learning operation in ML.NET starts by creating a Machine Learning Context. If we put it in terms of our ML.NET pipeline, creating the MLContext is the first step in the process. This is because it provides a way to create every part of the pipeline. Or in another words, once instantiated, it provides a way to create the components for data loading, feature extraction, training, prediction, and model evaluation. As you can see the MLContext class contains all the operations we need.
Create MLContext
There are two ways to instantiate MLContext
MLContext mlContext = new MLContext();Or you can use
MLContext mlContext = new MLContext(seed: 1);Let us look at the constructor signature
public MLContext (int? seed = default);As you can see, the machine learning context has an optional Int parameter. This is the Seed for MLContext random number generator. So, if you provide the seed parameter, MLContext environment becomes deterministic, meaning that the results are repeatable and will remain the same across multiple runs. For example, if you are creating a Machine Learning tutorial and you want your results to be replicable then you can provide this parameter. However, if you do not set seed, MLContext will use random numbers generator, and results will be different for each run. In real life, I recommend keep random components nondeterministic, which means not setting the seed parameter.
MLContext class definition
Constructors
- MLContext(Nullable<Int32>) – Create the ML context.
Properties
- AnomalyDetection – Trainers and tasks specific to anomaly detection problems.
- BinaryClassification – Trainers and tasks specific to binary classification problems.
- Clustering – Trainers and tasks specific to clustering problems.
- ComponentCatalog – This is a catalog of components that will be used for model loading.
- Data – Data loading and saving.
- Forecasting – Trainers and tasks specific to forecasting problems.
- Model – Operations with trained models.
- MulticlassClassification – Trainers and tasks specific to multiclass classification problems.
- Ranking – Trainers and tasks specific to ranking problems.
- Regression – Trainers and tasks specific to regression problems.
- Transforms – Data processing operations.
Events
- Log – The handler for the log messages.
Currently ML.NET supports the following types of Machine Learning:
- Binary Classification
- Multiclass Classification
- Regression
- Clustering
- Anomaly Detection
- Forecasting (Timer Series Data)
Binary Classification
Binary Classification is the task of classifying the elements of a set into two groups based on a classification rule. For example, in medical testing using this classification method we can determine if a patient has a certain disease or not.
Multiclass or multinomial classification
Multiclass or multinomial classification classifies instances into one of three or more classes. For example, given an image from some fruit, determine what kind of fruit is on the image: an apple, orange, or pear.
Regression
Regression analysis consists of a set of Machine Learning methods that allow us to predict a continuous outcome variable based on the value of one or multiple predictor variables. One of the best examples is the housing pricing problem. Eventually in this tutorial series we are going to build a regression model that can predict housing prices given a set of input variables. Input variables would be the square feet of the property, number of bedrooms, number of bathrooms etc. The output of course will be the predicted amount in USD.
In mathematics a variable can be continuous or discreet. If it can take on two real values such that It can also take on all real values between them, the variable is continuous in that interval. And that is exactly what we are working with here. A money amount can be anything between 0 and infinity. Although in a real-life scenario, the upper bound is not infinity but it can be a quite large number.
Clustering
Clustering is a Machine Learning technique that involves the grouping of data points. In theory if two data points are close to each other, we can deduct that they have similar properties and/or features. As a result, similar data points form clusters.
For example, let us look at ten images. Five images contain dog, and on the other five there is a cat. The five images containing a dog would naturally create a cluster. That is because the features of the data points would be prominent dog features. Although there are different breeds of dog, they still have a lot of in common. As a result, those images would form one cluster. On the other side, the cat images would form their own cluster. But this is just an example. It is never that easy to create a well separated clusters in a real-world scenario. To do that we need a good way to engineer good features. And we will see how to do that soon.
Anomaly Detection
Anomaly Detection is a process that finds the outliers of a dataset, those that do not belong. In other words, it is the identification of rare items, events and observations which raise suspicions by differing significantly from most of the data. A good example is detection of credit card fraud based on the amount spent. I have already created anomaly detection application in C#.
Anomaly Detection on CPU Waveform using K-Means
Forecasting
Forecasting is the process on making prediction based on one additional dimension. And that is time. There are so many prediction problems that involve a time component. Forecasting usually involves taking models fit on historical data and using them to predict future observations. It allows us to make future prediction based on a processed data points that occurred over a specific time frame. Time Series is a sequence of data points taken at successive, equally spaced points in time. The major components that we usually analyze are trends, seasonality, irregularity, cyclicity.
We will see all these Machine Learning models in action. But for now, it is good to know what each learning model tries to solve.
ML.NET Pipeline : Conclusion
Every Machine Learning operation in ML.NET Pipeline is started by creating a machine learning context. This context is the starting point of the pipeline. ML.NET encapsulates this context in MLContext type. This type has several properties that offer capabilities to start a specific machine learning task. But it also offers us a way to load and handle the data.
Up next we will see how to execute the first step towards building our Machine Learning model. We will start by loading the data.
best gold ira
February 9, 2024 at 11:02 pmThank you for this post, it has been totally helpful to me! Way simpler than anything else out there.
ubaTaeCJ
March 12, 2024 at 10:03 pm1
vpn code 2024
April 8, 2024 at 1:25 pmHi every one, here every one is sharing these kinds of experience, therefore
it’s pleasant to read this weblog, and I used to pay a
quick visit this website all the time.
Feel free to surf to my homepage: vpn code 2024
vpn coupon code 2024
April 11, 2024 at 12:28 pmEverything is very open with a very clear description of the issues.
It was truly informative. Your website is useful. Thanks for sharing!
Feel free to visit my webpage; vpn coupon code 2024