

Hello guys, and welcome to Introduction to Machine Learning in C# using ML.NET tutorial. This series of articles will teach you how to create, train and consume Machine Learning models in .NET
In this tutorial we are going to give you a full overview on what is ML.NET and how to use it. But we will also see how you can deploy the models you create.
As you already know in .NET you can create anything you want. Desktop, Web, Mobile, Game, IoT applications, and now Machine Learning models. And this is the focus of this entire blog.
Next Post in this tutorial series: How to build a ML.NET Pipeline
Lets get started…
What is ML.NET
ML.NET is nothing but a framework. It is an open source and cross-platform machine learning framework, that is built for .NET developers. Aside from the API provided, the framework also includes tools to help you build and train models easier. But, also to generate code in C#, so that you can learn how to consume the model, or how to retrain that model with your own code.
Microsoft also extends ML.NET with TensorFlow for Deep Learning scenarios. This is because the original ML.NET is more focused on traditional Machine Learning problems such as: Regression and Classification.
ML.NET is enterprise-ready framework. This is because Microsoft has been using ML.NET internally for more than eight years. In products like:
- Bing – for AD predictions
- Excel – for chart recommendations
- Power Point – for design ideas
- Microsoft Defender – for Antivirus Threat Protection
- Azure System Analytics – for Anomaly Detection
ML.NET runs anywhere
ML.NET is a framework you can run anywhere. You can run it on premises for creating, training, or consuming the model. You can also run it in Azure, or any other cloud technology. And the best thing is: ML.NET is a cross platform framework. Meaning it can run on Windows, Linux, Mac you name it.
Supported Frameworks:
- .NET Core (Natively)
- .NET Framework (Natively)
- Python with NimbusML (Python bindings)
Supported Process Architecture
- X64
- X32
Machine Learning Complexity
Machine Learning is complex. If you are a .NET developer, and you have not used ML in your projects, it can be perceived as a whole new world. So, there are different types of learning like Supervised and Unsupervised, but there are a lot of other algorithms that you might not be familiar with. So, ML.NET tries to simplify this. Instead of you doing all the research and learning about all these different types of scenarios, ML.NET abstracts this complexity for you. And we have already seen how ML.NET can help us classify images, without any previous knowledge
Like we mentioned earlier ML.NET comes with tooling. The Model Builder is an excellent example of that. It allows the user to pick a scenario, load the data and train the model. And the user can do all of this without any knowledge on Machine Learning. So, the only thing left to the .NET developer to do is to identify the scenario. And once you have identified the scenario then, you can also map it to a machine learning task.
For example, if you want to predict a number (Problem/Scenario) you can easily map this to a Regression task (Machine Learning Task). In case where you want to know if something is True or False you can map this problem to a Binary Classification task. If you want to detect an issue or a problem, that would be an Anomaly Detection task, and so on.
ML.NET Components
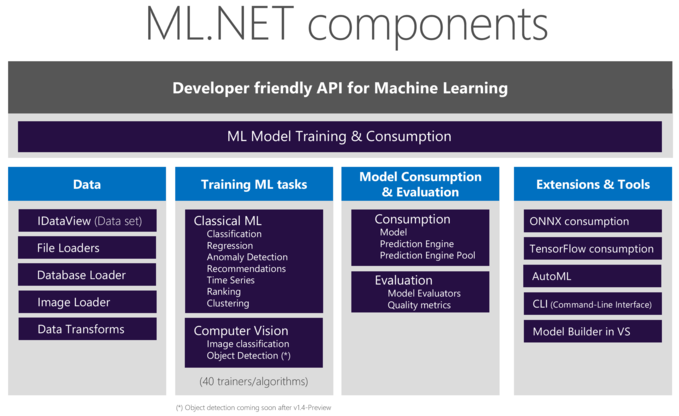
As we mentioned, ML.NET is a framework. It allows you to create, train and consume Machine Learning model. With its developer friendly API, it allows the user to train and deploy the model with just a couple of lines of code. And because it runs natively, you do not have to worry about if you create a model in Python then where are you going to run it? Will you run it in a Python environment, or are you going to run it on a Docker container in a different place. So, in this case you are not going to have that issue because it is native .NET.
ML.NET also hosts components for loading the data. IDataView interface allows you to load data from a file or a database. You can have a huge amount of data, which ML.NET will allow you to stream it from your data source. In other words, you do not have to load all the data in memory. This can be a huge problem in other frameworks which Microsoft solved it very elegantly.
The ML.NET API contains Machine Learning tasks. It supports Classification, Regression, Anomaly Detection, Recommendation, Time Series, Ranking, Clustering. But it also supports tasks from Computer Vision such as: Image Classification and Object Detection.
Then you have APIs for consuming that native model. It allows you to load the model from a zip file, so you can run or evaluate it. And the best thing of all is, that you can do it with as little as three lines of code.
ML.NET Extensions
And finally, there are extensions on TensorFlow for Deep Learning, ONNX integration that allows you to import or export models, which is a standard Machine Learning format. One of the more exciting features is AutoML.NET which is used by the Model Builder tool. It automatically explores different machine learning algorithms and settings. But it also automatically selects a trainer for us to ensure the highest possible accuracy on the provided data set. This allows the user to find the best model for a given scenario. Then there is the Model Builder tool which provides and easy to understand visual interface to build, train and deploy custom machine learning models.
Jupyter Notebook is an open-source web application that allows you to create and share documents that contain live code, equations, visualizations, and narrative text. And a great news for the ML.NET community is the fact that now you can run C# or F# code in Jupyter Notebooks and therefore run ML.NET code in it as well.
ML.NET Abstraction
I have been talking about abstraction for a while now. As you already know from software development, a good abstraction makes everything look easy. Abstraction matters. It hides the underlying complexity, and it allows the user to implement a more complex logic on top of the provided abstraction without understanding or even thinking about all the hidden complexity. Achieving a balanced level of abstraction is hard but, ML.NET does a great job at it. Remember, this is a framework that allows developers to enhance their applications, without you needing to learn data science or math to be able to use it. So, ML.NET democratizes Machine Learning by introducing it to .NET developers.
Like we mentioned earlier, ML.NET encapsulates machine learning algorithms and allows the user to call them as a function. It hides the complexity of the algorithm implementation behind a method. This allows developers to use ML algorithms without having a deep knowledge on how they work internally. In most scenarios the developer needs to learn how to use the algorithm and how to assess its performance. This is needed because you are bound to tweak some parameters at some point, to increase the algorithm performance. But that is about it.
ML.NET Problem Types
ML.NET currently supports supervised and unsupervised learning. Although there are more types of machine learning algorithms most of our scenarios belongs to one of these categories. We know that Microsoft is working hard to bring us even more learning models.
And here is the list of what we can do with ML.NET at the moment:
- Supervised Learning
- Regression
- Classification
- Binary Classification
- Multiclass classification
- Product Recommendation
- Unsupervised Learning
- Clustering
I will probably write separate articles explaining these list items individually. But for now, we will explain them as we go.
The Pipeline
Creating a machine learning system does not involve calling a single method. It is more than that. In most cases you will have to go through a process of data acquisition, transformation, and model building. To increase the performance of the model the data must pass through a well-designed pipeline.
Remember a machine learning model is nothing but a function trying to map input values as close as possible to their set of outputs. As a result, your model is as good as your data. And trust me on this one, data usually comes in a messy form that is in no way suited to be passed to our machine learning model. Therefore, we must process and transform it accordingly.
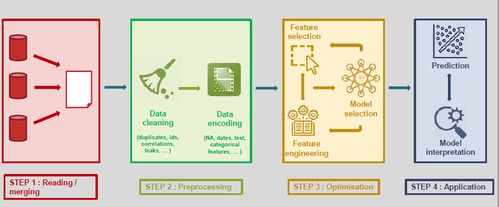
In the simplest case the process consists of the following steps:
- Data Acquisition
- Reading in or loading the data
- Data Transformation
- Prediction
- Accuracy Measuring
Data Acquisition
The process of gathering the data for training and evaluating the model.
Reading Data
ML.NET offers quite a variety of ways to load your data. It can be from a local text file to a server-side database, and anything in between really. It returns an IDataView which allows us to stream the data from the source. We will dig into this a little bit later. For now, it is good to know that we can load the data from multiple different sources.
Data Transformation
Like we said earlier, data almost always does not come in the right form for our ML.NET model. In most cases we need to transform it accordingly. For example, if you try to create a sentiment classifier (positive or negative) the model would not accept text. The text must be quantified. In other words, the sentences, words, or letters must be mapped to some number value. But there is a lot more to the Data Transformation process than this.
Prediction
The components we have described so far represent a machine learning pipeline. This pipeline can load data, transform it, and make a prediction. A pipeline is used to create an estimator. And we will use the estimator to generate our model.
Accuracy Measuring
We can measure the performance of the machine learning model in many ways. ML.NET offers several metrics. These metrics depend on the ML task we are performing.
Because this is only introduction to Machine Learning in C# using ML.NET we will not go any further. But, this ML.NET tutorial series dive deep into all the steps that are needed to create a ML.NET Model. We will explain everything from Data Acquisition, Data Transformation to creating a Prediction Engine.
Introduction to Machine Learning in C#: Conclusion
This is only Introduction to Machine Learning in C# using the ML.NET framework. Next we will discuss the Model Builder as a tool. This way we can properly introduce AutoML and the significance of it. Once, we are comfortable with the basics, we can introduce the API and start building and solving more complex problems.
Web Hero
February 24, 2024 at 2:46 pmПриветствую! Это Владислав из компании Web Hero.
Вы знали, что ошибки на сайте могут отпугнуть больше трети ваших потенциальных клиентов? Вот несколько фактов из исследований компаний:
1. Согласно исследованию компании Google, более 50% пользователей покидают сайт, если он загружается дольше, чем за 3 секунды. Медленная загрузка сайта часто связана с наличием технических ошибок.
2. Согласно исследованию компании Adobe, каждая ошибка на веб-сайте может стоить компании до 9% потерь в конверсии. Это подчеркивает важность минимизации ошибок на сайте для повышения доходности бизнеса.
3. Данные компании Akamai показывают, что даже короткие сбои в работе сайта могут привести к существенным финансовым потерям. Например, если сайт Amazon.com падает на 1 минуту, это может привести к потере доходов в размере до $220 000.
Мы предлагаем Вам профессиональную техподдержку для бесперебойной работы вашего веб-ресурса:
– Доработка функционала.
– Наполнение контентом.
– Адаптация под моб. устройства.
– Дизайн и проектирование.
– Обновление CMS и плагинов.
– Хостинг и домены.
– Интеграция с сервисами.
– Мониторинг и обслуживание.
Давайте обсудим, как усовершенствовать ваш сайт. Оставьте заявку на нашем сайте: wbhr.ru или свяжитесь со мной по email: sale.tp1@wbhr.ru.
Воспользуйтесь промокодом TPKOMPAS0224 и получите бесплатный тех. аудит вашего сайта.
ubaTaeCJ
March 12, 2024 at 10:10 pm1
vpn coupon 2024
March 31, 2024 at 8:40 pmThank you a bunch for sharing this with all of us you really know what you’re speaking about!
Bookmarked. Kindly also seek advice from my website =).
We will have a link change arrangement among us
Also visit my webpage :: vpn coupon 2024
Студия дизайна Милана
April 4, 2024 at 12:35 pmСтудия дизайна Милана воплотит Ваши самые смелые идеи о красивом доме в реальность.
Проектируем и реализуем дизайн интерьера: квартир, домов, студий, офисов,торговых помещений, кафе и ресторанов.
* Лучшие идеи для дизайна интерьера
* Оптимальный баланс технологий, форм и материалов
* Сочетание цены, качества и сроков.
Вдохновляйтесь своим окружением, ведь красота в деталях!
Тел.: +7 (967) 169-96-99
https://milana-design.ru/
vpn special coupon code 2024
April 8, 2024 at 2:08 pmIt’s amazing to pay a visit this web site and reading the views of all mates concerning this paragraph,
while I am also eager of getting know-how.
Here is my web blog … vpn special coupon code 2024
Ltn Led
April 10, 2024 at 7:03 pmСветодиодные светильники от производителя! Экономия от 30% при гарантии 5лет!
с 2012 года осуществляем производство и продажу светильников.
Промышленное, уличное, офисное и взрывозащищенное направление.
Заменяем дорогие брендовые светильники именитых заводов.
Сэкономили 82млн руб клиентам в 2022 заменив светильники в проектах,
наш ассортимент и возможности Ltn-Led.ru
почта для обсчета смет – strou-plo77@yandex.ru
vpn coupon 2024
April 10, 2024 at 8:34 pmVery good information. Lucky me I came across your blog
by accident (stumbleupon). I have saved it for later!
my web page – vpn coupon 2024