
Today we will talk about the significance of data handling. We will see how to preprocess data using ML.NET framework.
Data Preprocessing is one of the most important and difficult steps in machine learning project. But ML.NET provides various ways to handle messy data out of the box.
This is very important skill to have. Because all machine learning projects are different. And real-world datasets are usually not ready for consumption by ML.NET models.
If you remember from the last post, we said: “Garbage In – Garbage Out”. Almost always the data we are using to train ML.NET model, will need to go through couple of modifications. We can refer to this process as cleansing the data. And this step is crucial because the learning algorithm will fail to extract valuable insights. As a result, it will provide poor or even unacceptable results.
Although, we have already mentioned some data transformation techniques, this article will dive deeper into the topic. We will discuss some common practices to deal with different types of data preprocessing using ML.NET.
Like I said different machine learning tasks, require different data processing techniques. In one of the previous posts, we cover couple of ways to do that, but we never mentioned when to use which method.
Hopefully, this article will provide more insight.
The Machine Learning Process
Although, every single machine learning project is unique, and will go through different stages every time, there are some commonalities in the procedure.
It all starts with defining the problem. By looking at the data and the requirements you can tell a lot about it. Is it a regression, classification, or maybe other type of problem?
Sometimes you even need a domain expert to help you frame the prediction task. Or explore the data using statistics and visualization.
It all leads to you better understanding the objective, and the input so that you can define the problem and select the appropriate strategy to solve it.
Next step is data preparation. Data is messy and not fit to use in a machine learning algorithm. Today we will explore this process. More importantly, we will see what type of data transformations are required for a given ML.NET task.
Training is the next step, followed by an evaluation.
Once you have clean data you can pass it to the trainer. The algorithm should be able to extract valuable patterns and insights from the input. When the training step is completed, evaluation is performed.
Based on the evaluation results, you may decide that the model is performing on a satisfactory level. Or that the ML.NET model might need additional work. However, these two steps are out of the scope for this article. We will discuss them in more details in real projects.
Today we will focus only on the second step.
Preprocess data using ML.NET
Data preprocessing is the most important phase in a machine learning process. This is because data can be convoluted and messy in its raw state.
This step is also referred as data preparation. And it is specific to the input dataset, requirements and the machine learning algorithms that will be used in the project.
For example, in a sentiment analysis scenario, raw data in a text form cannot be passed to an algorithm. The ML.NET trainer needs numeric values, so the words must be transformed accordingly.
Image classification project may work better, or faster when given images in grayscale format.
Missing or faulty data is also a big problem. It may confuse the algorithm.
Identifying the inputs that are most relevant to the task also happens here. Please note that not all data points carry valuable information.
We can also create new variables from available data. Or do a dimensionality reduction to create a more compact projections of the data set.
So, let’s get started
Types of Data
Data comes in all different types:
- Numeric Data
- Text Data
- Categorical Data
- Location Data
- Image Data
- Video Data
- Sound Data
Numeric Data
Numeric data is exactly what the name infers. Data comprised of numerical values. Integers and floats. For example, the age of a person, size of a property in square feet or the dollar amount spent on taxi fare.
Textual Data
This type is represented with strings. Strings containing person’s name, address, or phone number. Email address, an amazon review or feedback and text messages.
Categorical Data
Categorical data is just an enumeration over a list. Best example is the gender field, postal codes, or names of the blocks in a city. Categorical data can take one of many predefined categories as a value. It’s a closed set of potential values a user can choose from.
Location Data
It is exactly what the name implies. Location of a person or a place. Geo coordinates are acceptable values for this type.
ML.NET algorithms can accept and handle image data, video, and sound as well, when properly preprocessed.
The transformation of the data depends on its type.
In the next section we will go over different examples on how to preprocess data using ML.NET.
Numerical Data Transformation in ML.NET
The following methods are available for numerical data transformations:
- Mean Normalization
- Log Mean Normalization
- Unit Norm Normalization
- Global Contrast Normalization
- Density Normalization
- Min-Max Normalization
All of these methods can be found under the MLContext instance Transforms property.
Normalization is a technique applied as part of data preparation process for machine learning. The objective is to change the values of numeric column in the dataset to a common scale. But, without distorting the differences in the ranges of values.
Usually, the values are scaled in a range between 0 and 1, which is ideal for the input to a machine learning algorithm that employs some kind of regression. But the benefits of this operation don’t end here. The scaling improves the numerical stability of the model, but it can also speed up the training process. Standardization also gives “equal” considerations for each feature.
All these normalization schemes are essentially an estimator that transforms the input data to transformed data as an IDataView.
Let’s look at a simple example:
Data Normalization Example
Start by creating the machine learning context and loading the data:
var mlContext = new MLContext();
var data = mlContext.Data.LoadFromEnumerable(Data.Get()); The data is defined with the following type:
public class InputModel
{
public float Size { get; set; }
public string Type { get; set; }
public string Description { get; set; }
public float Price { get; set; }
} And it represents a real estate property. Size field holds a float value of the square meter size of the estate. The property can be categorized as a house or apartment. A small description expressed by a free text is also part of the input dataset and understandably a price is assigned.
This type of problem is usually solved with regression. Which in turn means that the input data must be normalized. So, let’s normalize the Size property.
Min Max Normalization technique
var pipeline = mlContext.Transforms.NormalizeMinMax("SizeNorm","Size"); NormalizeMinMax method creates an NormalizingEstimator which scales the data based on the observed minimum and maximum values. By default, data is normalized between 0 and 1.
The input column is “Size”, and the output scaled values are placed in the new column “SizeNorm”.
This works well if we want to normalize a single column. But if we want to execute the same operations on multiple columns, we must use the following code:
var pipeline = mlContext.Transforms.NormalizeMinMax(new InputOutputColumnPair[]
{
new InputOutputColumnPair("SizeNorm", "Size"),
new InputOutputColumnPair("NoOfRoomsNorm", "NoOfRooms")
}); The example above shows how can we normalize the data for two different columns.
After that all we have to do is transform the data and preview it.
var transformedData = pipeline.Fit(data).Transform(data);
var preview = transformedData.Preview(); And here is a preview sample

A house of 1100 square feet is scaled down to a range between 0 and 1. And, we are storing that value in a new column “SizeNorm”. Exactly what we wanted.
This is a very common normalization technique. Each value is decreased by the following factor. First, minimum values are subtracted from each value, and then the result is multiplied by the reducing factor
1 / (max-min)
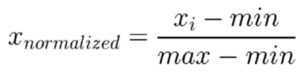
Categorical Data Transformation in ML.NET
The following methods are available for categorical data transformation:
- One-hot encoding
- One-hot hash encoding
Most of the times it is very tempting to simply convert a categorical data point to a numeric value. However, this technique adds a bias to the model. As a result, the prediction will be wrong.
For example, if we have two categories in our dataset: “House” and “Apartment”. And we encode them as 1 and 2 respectively the machine learning algorithm will recognize “Apartment” as a better category simply because of its value. This doesn’t make any sense.
Therefore, we need to transform this column in two additional columns. “Is_Apartment” and “Is_House”. The one-hot encoding technique will generate a 2-dimensional vector for each property.
For example, to denote a house we will use a vector consisting of the following values: [1, 0] and to denote an apartment [0, 1]. This technique removes the bias form the equation.
Instead of having one column for “Type” we now have two columns, each representing the presence of “Apartment” or “House” in the “Type” column.
Let’s see this in action
One Hot Encoding Example
var pipeline = mlContext.Transforms.Categorical.OneHotEncoding(new InputOutputColumnPair[]
{
new InputOutputColumnPair("TypeEncoded", "Type")
}); And here are the results

TypeEncoded is the new addition to the IDataView. As you can see the “House” string is encoded in the value 1, which in turn is encoded in a sparse vector of size 2. That vector has the following value: [1, 0]
However, the “Apartment” string gets encoded in the value 2 and its vector values are: [0, 1]

Now let’s look at the following problem. What if we have a value with different casing?
For example, what if one data point contains the word: “hoUSE”? In that case One Hot Encoding will just create a new category. But that is not right. It is the same category as “House” but with different casing.
To solve a problem like this we need One Hot Hash Encoding method. It works in the same principle as One Hot Encoding.
The only difference is the presence of a hash function. A hash function maps data of an arbitrary size onto a number with a fixed range. This in turn will produce the same hash code for all different looking, yet same categorical values.
To test it just swap the method name in the example.
In conclusion, this is the proper way of transforming categorical data.
Transformation of Text Data using ML.NET
Next on how to preprocess data using ML.NET is text handling. Text in its raw form cannot be used in machine learning. You will need to convert it to a numeric type.
Here are the methods available for text transformations
- FeaturizeText
- TokenizeIntoWords
- TokenizeIntoCharacterAsKeys
- NormalizeText
- ProduceNGrams
- ProduceWordBags
- ProduceHashedNGrams
- RemoveDefaultStopWords
- RemoveStopWords
- LatentDirichletAllocation
- ApplyWordEmbedding
All of these methods provide a way of processing textual data.
For example, Featurize Text provides the user with functionality of converting string into a numeric floating-point representation. Tokenize into Words method splits the string into an array of words. Normalize text changes the case of the text, removing punctuations, numbers and so on.
For example:
var pipeline = mlContext.Transforms.Text.FeaturizeText("DescriptionFeatures", "Description"); This statement takes the string from the “Description” column and it creates a numeric floating-point representation in “DescriptionFeatures” column.

We can verify that ML.NET added a new column and created a numeric vector of size 474,153. Instead of using the textual form of the input we can now use its numeric counterpart. This is a form that a machine learning accepts as an input.
Conclusion
Finally, let’s try and quickly summarize what we know by now.
In this article we demonstrated how to preprocess data in ML.NET.
Normalization
Normalization is the process of making every data point in the same range for regression algorithms. It allows the ML.NET model to converge towards a solution faster. In other words, it will speed up the training process.
But usually, large numbers as features create bias in the model. A regression algorithm will look at a column with large values and think that, that column is of a big significance. Even though it is not.
We will verify this statement when we implement the Linear Regression algorithm from scratch. But for now, it is important to remember that regression algorithms do require data normalization.
Removal
Removal is the process of removing faulty or bad data points. Commonly used words in a sentence such as: “a”, “and”, “an”, “of” and others do not carry any insightful information. Because of that, data scientists filter out these so-called Stop Words. If you want to build a sentiment classifier, punctuation is also something that you don’t need to analyze.
Sometimes removing is a preparatory step performed on textual data before they can be transformed to numerical representations. And later those numerical representations can be normalized.
Although the example talks about text data, we can perform this step on other types of data as well.
Featurization
Featurization is the process of creating a numerical representation of the data. It is impossible to use any machine learning algorithm with anything than numeric vector. Extracting features from the raw data are a while new discipline in its own right. We will see many examples involving the featurization process.
One of the ways to featurize a text, is to assign a number (most often the frequency occurrence) to each word. Or you can simply encode each word to an integer value.
The benefits of featurization are manyfold. The first one is that it really helps in comparison with other seemingly similar things in the world. Instead of comparing two sentences character by character, we can simply calculate the cosine similarity between two vectors representing those two sentences.
This way the algorithm becomes scalable.
Missing Values
Missing Values are the real challenge when trying to clean the data. Simply because missing values are hard to fill. But if left as is then the machine learning algorithm might perform really bad.
There are two ways to solve the problem.
Augmenting missing data which allows us to choose appropriate substitute for the missing value. But then what could be a possible good substitute? ML.NET provides couple of methods like: Maximum, Minimum, or the Default method to fill in the missing values in the respective column.
Removing rows/columns with missing data is another obvious solution.
Ultimately it is up to you. Through a process of trial and error, you should be able to get to an acceptable solution. It is really hard to assume which method might work best for a given scenario, so you need to test and see which missing value replacement strategy works best with your model.
ML.NET also offers data transformation methods for image processing, deep learning and for time series data type. They are out of the scope of this article because we will see them in action on real-world projects.
Finally, we know how to preprocess data using ML.NET. Next, we will start solving problems like regression or classification.
Previous Post: How to Train ML.NET Model
The source code for this tutorial can be downloaded from the following link:
ubaTaeCJ
March 12, 2024 at 10:11 pm1
Trending Hairstyles
March 18, 2024 at 1:57 pmIts like you read my mind! You seem to know so much about this, like you wrote the book in it or something. I think that you can do with some pics to drive the message home a bit, but instead of that, this is excellent blog. An excellent read. I’ll definitely be back.
Hairstyles
March 19, 2024 at 2:06 pmI think that is among the most vital info for me. And i’m happy studying your article. However want to observation on few basic things, The web site taste is ideal, the articles is in point of fact excellent : D. Just right task, cheers
Hairstyles
March 21, 2024 at 7:24 amOne more thing to say is that an online business administration study course is designed for students to be able to smoothly proceed to bachelors degree education. The 90 credit college degree meets the other bachelor college degree requirements when you earn your current associate of arts in BA online, you should have access to the latest technologies in this particular field. Some reasons why students want to be able to get their associate degree in business is because they’re interested in this area and want to receive the general schooling necessary prior to jumping right bachelor college diploma program. Many thanks for the tips you actually provide in your blog.
Trending Hairstyles
March 23, 2024 at 12:59 amSimply desire to say your article is as surprising. The clearness in your put up is just spectacular and i could assume you’re an expert in this subject. Well together with your permission allow me to take hold of your feed to keep up to date with drawing close post. Thanks a million and please carry on the rewarding work.
Haircuts
March 23, 2024 at 5:31 amI’ve been surfing online more than three hours today, yet I never found any interesting article like yours. It is pretty worth enough for me. In my view, if all webmasters and bloggers made good content as you did, the web will be a lot more useful than ever before.
KAYSWELL
March 26, 2024 at 1:16 amExcellent blog right here! Additionally your web site so much up very fast! What host are you using? Can I am getting your affiliate hyperlink for your host? I wish my website loaded up as fast as yours lol
Hairstyles
March 26, 2024 at 11:39 pmThank you for another wonderful article. The place else may anybody get that type of information in such a perfect way of writing? I’ve a presentation next week, and I’m at the look for such information.
Haircuts
March 29, 2024 at 6:37 amToday, with the fast chosen lifestyle that everyone is having, credit cards have a big demand throughout the economy. Persons from every field are using credit card and people who not using the credit card have arranged to apply for even one. Thanks for revealing your ideas in credit cards.
vpn special code
April 1, 2024 at 4:05 pmIt’s not my first time to pay a visit this web site, i am visiting this website dailly and obtain good facts from here daily.
My web blog … vpn special code
vpn coupon code 2024
April 2, 2024 at 5:48 amI don’t even know how I finished up here, but I thought this submit was
once good. I don’t recognize who you are however definitely you’re going to a famous blogger
if you happen to aren’t already. Cheers!
Here is my page; vpn coupon code 2024
vpn special coupon code 2024
April 2, 2024 at 3:47 pmHello there! I could have sworn I’ve been to this site
before but after browsing through some of the posts I realized it’s
new to me. Regardless, I’m definitely happy I found it
and I’ll be book-marking it and checking back often!
my blog post – vpn special coupon code 2024
vpn coupon code 2024
April 6, 2024 at 10:09 amexcellent issues altogether, you simply received a new reader.
What may you suggest in regards to your publish that you made some days ago?
Any certain?
Feel free to surf to my web-site – vpn coupon code 2024
vpn special
April 6, 2024 at 9:40 pmIt’s very trouble-free to find out any matter on net as compared to books,
as I found this paragraph at this web site.
Here is my web page: vpn special
vpn code 2024
April 8, 2024 at 7:41 amI am really pleased to read this blog posts which includes tons
of valuable information, thanks for providing these kinds of data.
my site … vpn code 2024
vpn special coupon code 2024
April 11, 2024 at 2:33 amWhen someone writes an piece of writing he/she
keeps the idea of a user in his/her mind that how a user can be aware of it.
So that’s why this article is great. Thanks!
Here is my web-site … vpn special coupon code 2024