
In this article we will see how to implement the Q Learning algorithm in C#. Here is the demo application we’re going to build today
Q Learning algorithm in C# Project Files: Download
Introduction to Reinforcement Learning
Reinforcement Learning is a process by which organisms acquire information about stimuli, actions, and context that predict positive outcomes. It can also modify behavior when a novel reward occurs, or the outcome is better than what we were expecting.
In other words, we give reward as a stimulus to a human or some other animal to alter its behavior. The reward typically serves as reinforcer.
We have all done it. Reinforcement Learning is teaching your dog to do tricks. You provide treats as a reward, if your pet performs the trick, otherwise you punish him by taking away the goodies. So, if you are a pet owner, you have probably trained and rewarded your pet after every positive behavior.
As humans, we also have experienced the same. Positive outcomes come with a reward. However, negative outcomes are punishable.
Reinforcement Learning in C#
To harness the full potential of AI we need an adaptive learning system. And Reinforcement Learning is one of those. We can use this Q Learning algorithm to solve a real-world problem through trial-and-error. It is a type of Machine Learning technique that enables an agent to learn in environment using feedback from its own actions and experiences.
The Reinforcement Learning paradigm is different than supervised one because it does not require a labelled input/output pairs to be presented. Instead, the goal is to make a sequence of decisions that would maximize the total cumulative reward of the agent. Therefore, the agent trains on achieving its goal in an uncertain and complex environment.
Reinforcement Learning Applications
Reinforcement Learning algorithms can be used to automatically learn how to allocate and schedule computer resources to waiting jobs, with the objective of minimizing the average job slowdown.
In the paper “Reinforcement learning-based multi-agent system for network traffic signal control”, researchers tried to design a traffic light controller to solve the congestion problem.
Reinforcement Learning is applied in the field of Robotics, Chemistry, Game development and Deep Learning.
This blog post showed the very basics of Reinforcement Learning by using the Q Learning algorithm to solve the “Rooms problem” in C#. In the next post we will use some of C# visualizing components to better understand how Q Learning works in a more complex environment.
Q Learning Terminology
We have been discussing about agent, environment, actions, and rewards. Let us see what all those terms mean.
- Agent represents the subject that interacts with the environment. The decision maker.
- Environment is the world in which the agent resides.
- Action is a limited set of operations that the Agent can perform in the Environment
- State is the current situation of the agent in the Environment
- Reward is a scalar value representing the feedback from the Environment after executing an Action
Understand Reinforcement Learning and Q Learning by building C# application
In most cases Reinforcement Learning is best described through a game example. In this example we will be using the Q Learning algorithm and C# to make a robot learn how to navigate a map. The map contains rooms. It has a start point and a target point. The robot can navigate between rooms if they are connected to each other. The initial point represents the position at which the robot will be starting. Similarly, the target point represents the goal state.
Transcribe the problem into a Q Learning Terminology
The agent in our example represents the robot. He is the one that makes decisions and interacts with the environment. The closed off, two-dimensional grid is the agent’s world-environment.
Actions are defined by all the possible directions the robot can go. In our example the robot can do one action, and that is to go from one room to another.
After the agent executes an action it goes into a certain state. The State is the current position of the robot in the Environment. Agent receives award when he finds his end point.
A Robot Problem
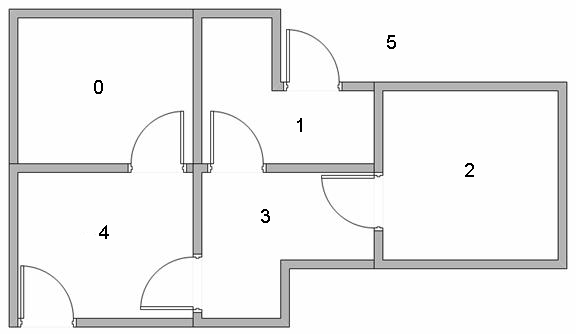
Let’s look at the problem we are going to solve. Say we have a robot. The goal of the robot is to exit this little apartment. In other words, the end goal is to go outside (state number 5). The rooms are connected by doors. But not every room is accessible from anywhere. For example, room 4 is accessible by room 0 and room 3 but not by room 1. Having said that, how do we go outside?
This problem can be solved in many ways. But, instead of measuring distance, we will rate sequences based on utility of getting to a room. For example, if the goal is to go outside, getting to room 1 is better than getting to room 0. And with this, we just described the essence of the Q Learning algorithm.
Before we continue, let’s look at the solution first.
Q Learning: C# Application Output
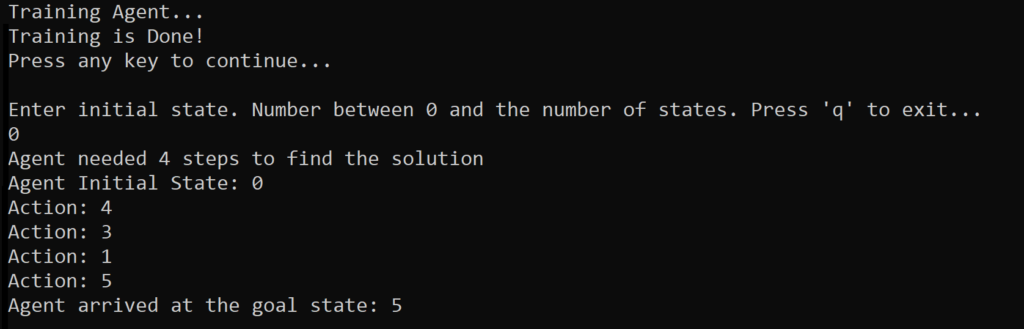
For this Q Learning tutorial, we are going to build a small C# Console Application. The goal of the app is to train a robot to solve the room problem.
But before we resolve the issue, we must first train the agent. Training is the process where the agent familiarize itself with the environment and builds the most optimal policy. We will discuss what optimal policy is in shortly.
The C# Console output shows us that if the agent starts in Room 0 and enters Room 4, goes through Room 3 to Room 1, it can find the exit. It took 4 steps to solve the problem.
Q Learning Setup
In order to continue coding, we first need to discuss the policy. The policy consists of states and actions. In our problem a state is the room that robot is in. The action is going from one room to another. So, a policy is an agent’s strategy. As you can see there are multiple possible policies for any given state. Obviously, some policies are better than others, and there are multiple ways to assess them. But the goal of Reinforcement Learning is to learn the best policy.
Now we are ready to write some code.
Reinforcement Learning: A C# Source Code Walkthrough
Before we start implementing the Q Learning algorithm, let’s set up the rooms problem in C#.
Rewards Matrix
double[][] rewards = new double[6][]
{
new double[]{-1, -1, -1, -1, 0, -1 },
new double[]{-1, -1, -1, 0, -1, 100},
new double[]{-1, -1, -1, 0, -1, -1},
new double[]{-1, 0, 0, -1, 0, -1},
new double[]{ 0, -1, -1, 0, -1, -1},
new double[]{-1, 0, -1, -1, -1, -1}
};This is the rewards matrix. This matrix is represented as an array of arrays using C# syntax. The rows represent the 6 possible states the agent can end up in. Starting from Room 0 to Room 5. And the columns represent the action. An action allows the agent to move from one room to another. One of the most important components of Reinforcement Learning is the reward matrix. So, let’s investigate this a little further.
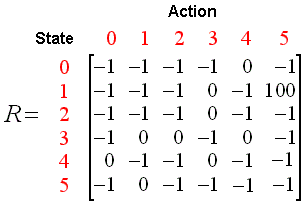
A Reward Matrix offers the reward that agent is going to get given his current state and action. Let’s look at a simple example:
If agent resides in State 0 (which equates to Room 0) and stays in place (stays in Room 0) it has a negative reward of -1. This is because this state is an invalid state. The agent must move. Same goes if the agent is in Room 0 and tries to go to Room 1. From the matrix you can see that there is a negative reward of -1 because it is illegal (agent cannot enter Room 1 from Room 0). But, if the agent leaves Room 0 and tries to enter Room 4 he get’s a reward of 0. This is because we are not rewarding a move operation. But generally, 0 means that this action is valid. The only reward given is when agent leaves Room 1 and enters Room 5. It gets a huge reward quantified as 100 points.
This matrix represents our Q Learning problem inside the C# application.
Q Learning Actions
public double GetReward(int currentState, int action)
{
return rewards[currentState][action];
}
We extract the reward from the reward matrix by combining the currentState and action.
In reinforcement learning the agent makes the decisions on which actions to take at each time step.
public int[] GetValidActions(int currentState)
{
List<int> validActions = new List<int>();
for (int i = 0; i < rewards[currentState].Length; i++)
{
if (rewards[currentState][i] != -1)
validActions.Add(i);
}
return validActions.ToArray();
}
The GetValidAction procedure allows us to extract all valid actions given the current state of the agent. As you can remember a valid action is an action that has a number larger than 0.
A Jagged Array declaration in C# represents an array or arrays.
In reinforcement learning we need to define our problem such that it can be applied to satisfy our reward hypothesis. When the goal is reached, the maximum reward is delivered.
public bool GoalStateIsReached(int currentState)
{
return currentState == 5;
}
And of course, the goal state is reached if the current state we are in is equal to 5 (We are outside). Using the C# syntax all we need to do is compare the currentState value against the final state.
Q Learning Recap
- Q Learning is a model-free reinforcement learning algorithm
- The goal is learning the optimal policy or the quality of actions from a state over time
- Requires that is a finite Markov Decision Process
- Learns the optimal policy by maximizing the expected Q value of the total reward for all the states, starting from the current state
- Reinforcement Learning is the science of decision making
Q Learning Algorithm in C#
Introducing the Q Table
In order to implement the algorithm, we need to introduce the Q Table.
The Q Table represent just a simple look up table where later we will calculate the maximum expected future reward for action at any state. This table will guide us to the best action at each state. In the Q Table the rows represent the rooms (states) and columns are the actions (same as the reward matrix). Each element in the Q Table will be the maximum expected future reward that the robot will get if it takes that action at that state. At the beginning the Q Table will be populated with zeros. But as we train, the agent actions will improve the table. The whole process centers around improving our Q Table.
Training the agent
The training process starts by calling the TrainAgent and providing the maximum number of train iterations.
public void TrainAgent(int numberOfIterations)
{
for(int i = 0; i < numberOfIterations; i++)
{
int initialState = SetInitialState(_qLearningProblem.NumberOfStates);
InitializeEpisode(initialState);
}
}
On each iteration we first initialize the starting state of the agent. We choose the initial state (Room) at random. Then we call InitializeEpisode and try to get to the end goal.
Q Learning Algorithm in C#: Episode Initialization
private void InitializeEpisode(int initialState)
{
int currentState = initialState;
while (true)
{
currentState = TakeAction(currentState);
if (_qLearningProblem.GoalStateIsReached(currentState))
break;
}
}
We execute the InitializeEpisode method until we reach our goal. And we reach our goal by taking actions. What this procedure does is it takes the current state, chooses an action and returns the new state of the agent. If that state is the end state it will break out of this training episode. Next, let’s look at the C# code for TakeAction method.
private int TakeAction(int currentState)
{
var validActions = _qLearningProblem.GetValidActions(currentState);
int randomIndexAction = _random.Next(0, validActions.Length);
int action = validActions[randomIndexAction];
double saReward = _qLearningProblem.GetReward(currentState, action);
double nsReward = _qTable[action].Max();
double qCurrentState = saReward + (_gamma * nsReward);
_qTable[currentState][action] = qCurrentState;
int newState = action;
return newState;
}
Given the current state of the agent we need to get the valid actions. As we discussed earlier not all actions taken from a state are valid. If you remember there are rules. An agent cannot get from Room 0 to Room 1 directly. So, we must filter this invalid action.
Next, we enter exploration mode. There are many ways how we can decide which action to choose. But this implementation chooses at random. We will go over Exploration Policies in some later post.
Math of Q Learning
Now we need a little bit of math.
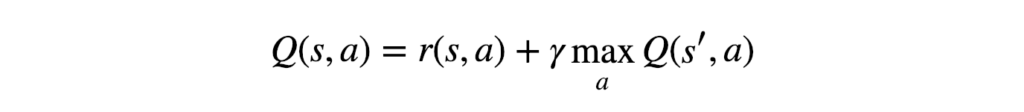
The C# equivalent to this mathematical problem can be written as:
saReward + (_gamma * nsReward);What this equation represents is how we update our Q Table values. The saReward variable holds the reward value the agent has gotten by executing an action in the current state r(s, a). NsReward variable gets the maximum future reward the agent can score given the new state s’ and all possible actions at that new state maxQ(s’,a). And the only thing left to do is to multiply that by the Discount Rate or gamma.
Gamma is used to balance immediate and future reward. From our update rule above you can see that we apply the discount to the future reward. Typically, this value can range anywhere from 0.8 to 0.99. Because of that we use the built in C# floating point type of double to represent this parameter.
Once we execute the equation code, we can update the Q Table with that value. Then we simply return the new state we are in.
If you are interested in the mathematical intuition behind this equation, there will be another post going in math details of how and why this algorithm works. For now, we will concentrate on the concrete implementation.
Q Learning Algorithm in C#: The Main Method
Let’s test the QLearning class we just implemented. Here is the C# code listing
static void Main()
{
var qLearning = new QLearning(0.8, new RoomsProblem());
Console.WriteLine("Training Agent...");
qLearning.TrainAgent(2000);
Console.WriteLine("Training is Done!");
Console.WriteLine("Press any key to continue...");
Console.ReadLine();
do
{
Console.WriteLine($"Enter initial state. Number between 0 and the number of states. Press 'q' to exit...");
int initialState = 0;
if (!int.TryParse(Console.ReadLine(), out initialState)) break;
try
{
var qLearningStats = qLearning.Run(initialState);
Console.WriteLine(qLearningStats.ToString());
var normalizedMatrix = qLearning.QTable.NormalizeMatrix();
Console.Write(normalizedMatrix.Print());
}
catch(Exception ex)
{
Console.WriteLine($"Error: {ex.Message}");
}
}
while (true);
}
First, we create a new instance of the class and set gamma to 0.8 (a recommended value for the only Q Learning parameter). We declare and apply our Room Problem through the RoomsProblem instance.
Then, we train the agent using 2000 iterations. After that we are ready to test the Q Learning algorithm.
We simply choose the starting state of the agent and call the Run method. This procedure will return a QLearningStatistics instance that contains the initial state, end state as well as all the actions the agent had to make, to end in the goal state.
Let’s see the C# implementation
public class QLearningStats
{
public int InitialState { get; set; }
public int EndState { get; set; }
public int Steps { get; set; }
public int[] Actions { get; set; }
public override string ToString()
{
StringBuilder sb = new StringBuilder();
sb.AppendLine($"Agent needed {Steps} steps to find the solution");
sb.AppendLine($"Agent Initial State: {InitialState}");
foreach (var action in Actions)
sb.AppendLine($"Action: {action}");
sb.AppendLine($"Agent arrived at the goal state: {EndState}");
return sb.ToString();
}
}Analyzing the result
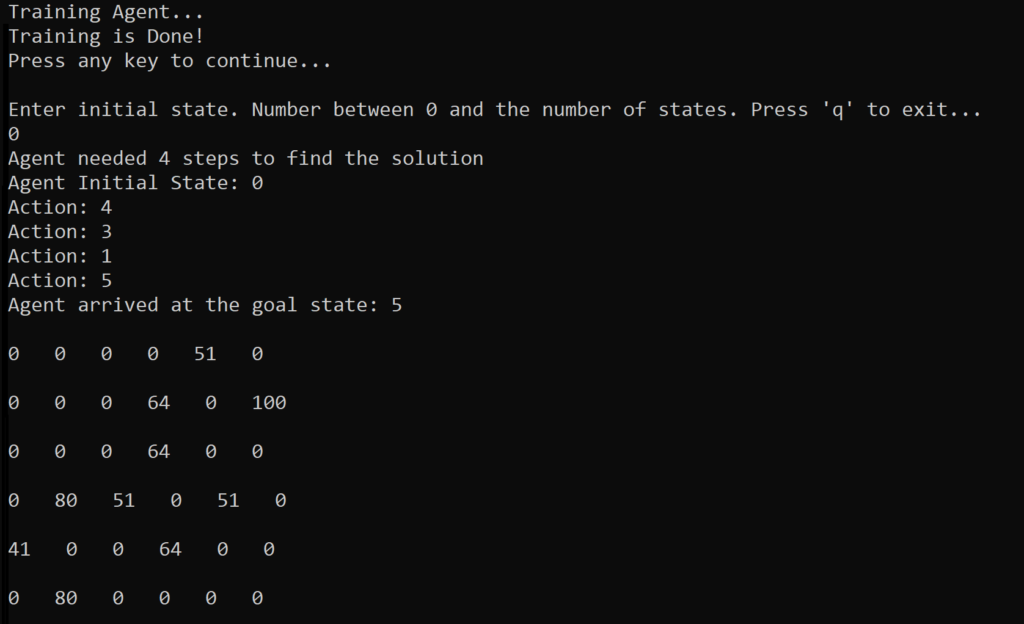
On this image we can see the normalized Q Table printed out like this:
0 0 0 0 51 0
0 0 0 64 0 100
0 0 0 64 0 0
0 80 51 0 51 0
41 0 0 64 0 0
0 80 0 0 0 0 This means that if we are in the Room 0 (Row 0), we are going to maximize the reward by going into Room 4 (That is, do an action that moves us to Room 4 – represented by Column 4). The max reward is 51 (normalized). Once we are in Room 4, we move to the forth row of the matrix. The maximum reward there is 64. That is, we take action and move to Room 3 (Column 3). Once in Room 3 we are after the action that holds the most benefit. And that is to get into Room 1 (Reward of 80). From Room 1 we can maximize the reward by going outside (Final State 5).
Q Learning Algorithm in C# : Conclusion
This is a very simple implementation of the Q Learning algorithm using the C# language. We will investigate and implement more visual samples with Q Learning, before we dig into Deep Q Learning.
best gold ira rollover
February 5, 2024 at 4:58 pmYour post unsettles me …
Alok
February 18, 2024 at 2:37 amthe source code link in the comment isn’t working
Hottest Hairstyles
March 26, 2024 at 6:31 amI have been reading out some of your articles and i must say pretty nice stuff. I will definitely bookmark your blog.
Haircuts
March 29, 2024 at 2:21 amexcellent submit, very informative. I ponder why the opposite specialists of this sector don’t notice this. You should continue your writing. I am sure, you have a huge readers’ base already!
vpn special coupon code 2024
April 5, 2024 at 1:37 amAttractive section of content. I just stumbled upon your site and
in accession capital to assert that I acquire actually enjoyed account
your blog posts. Anyway I’ll be subscribing to your augment and even I achievement
you access consistently rapidly.
My webpage :: vpn special coupon code 2024
vpn special code
April 6, 2024 at 7:49 amThank you for any other informative site. Where else may just I get that kind
of information written in such an ideal way? I have a
project that I am simply now running on, and I have been at the glance out
for such information.
My website – vpn special code
vpn special coupon code 2024
April 7, 2024 at 5:34 pmI have read so many content regarding the blogger lovers however this post
is actually a pleasant post, keep it up.
My webpage :: vpn special coupon code 2024
Haircuts
April 9, 2024 at 8:03 pmToday, I went to the beach front with my children. I found a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the shell to her ear and screamed. There was a hermit crab inside and it pinched her ear. She never wants to go back! LoL I know this is entirely off topic but I had to tell someone!
vpn special coupon code 2024
April 11, 2024 at 3:30 pmWay cool! Some very valid points! I appreciate you writing
this write-up and the rest of the site is also really good.
Feel free to visit my web site: vpn special coupon code 2024
Hottest Hairstyles
April 13, 2024 at 12:35 amI would like to thank you for the efforts you have put in writing this site. I am hoping the same high-grade website post from you in the upcoming also. Actually your creative writing skills has encouraged me to get my own site now. Actually the blogging is spreading its wings fast. Your write up is a good example of it.
Hottest Hairstyles
April 15, 2024 at 1:53 amThanks for the auspicious writeup. It in fact used to be a enjoyment account it. Look complex to far added agreeable from you! By the way, how can we keep up a correspondence?