

In this post, I am going to demonstrate how to create Article Classification with K-Means and C#.
This project can be seen as a text classification problem. Text Classification is one of the wildly used natural language processing (NLP) applications in different business problems.
If you are interested in doing the same tutorial using ML.NET, you can find the article here: Article Classification with ML.NET
What is Text Classification
Text classification is the task of assigning a set of predefined categories to free-text. Text classifiers can be used to organize, structure, and categorize pretty much anything. New articles can be organized by topics, support tickets can be organized by urgency, chat conversations can be organized by language, brand mentions can be organized by sentiment, and so on.
In the presented demo with this tutorial, we are classifying articles scraped from Wikipedia.
Article Classification with K-Means
Before we start this tutorial it is very important for you to have knowledge on K-Means. You can see how this algorithm is implemented and how it works from this post. Read it, download and understand the code then come back and continue from here.
If you wish to use a third party library to complete the project, you can check Accord.NET and its article on K-Means. It’s a great library with a pretty extensive documentation and examples.
Getting Started with Text Vectorization for Article Classification with K-Means
Text Vectorization is the process of converting text into numerical representation. Here is some popular methods to accomplish text vectorization:
- Binary Term Frequency
- Bag of Words (BoW) Term Frequency
- (L1) Normalized Term Frequency
- (L2) Normalized TF-IDF
- Word2Vec
Before we convert our articles in the appropriate numerical representation (vector), we will first do a little bit of text preprocessing.
Text Preprocessing
Before doing any natural language processing tasks, it’s necessary to clean up the text data using text preprocessing techniques.
As the first step, we need to load the content of each article and check the regular expression to facilitate the process by removing the all non-alpha-numeric characters. We call such a collection of texts a corpus.
string fileContent = File.ReadAllText(file);
processedFile = Regex.Replace(fileContent, "[^a-zA-Z ]", "");Next step, we transform the corpus into a format by doing tokenization.
Tokenization
In a nutshell, tokenization is about splitting strings of text into smaller pieces, or “tokens”. Paragraphs can be tokenized into sentences and sentences can be tokenized into words.
string[] words = item.Text.Split(' ');Normalization
Normalization aims to put all text on a level playing field, e.g., converting all characters to lowercase
Noise Removal
Noise removal cleans up the text, e.g., remove extra whitespaces.
Bag-of-Words Models (BoW)
First, we need to create a universe of all words contained in our corpus of downloaded articles form Wikipedia, which we call a dictionary. Then, using the stemmed tokens and the dictionary, we will create bag-of-words models (BoW) to represent our articles as a list of all unique tokens they contain associated with their respective number of occurrences.
private void btnWord2Vec_Click(object sender, EventArgs e)
{
wordFrequencyDictionary = new Dictionary<string, int>();
foreach(TrainItem item in trainingDataSet)
{
string[] words = item.Text.Split(' ');
foreach(string word in words)
{
string wordLowerCaps = word.ToLower();
if (wordFrequencyDictionary.ContainsKey(wordLowerCaps))
{
wordFrequencyDictionary[wordLowerCaps] += 1;
}
else
{
wordFrequencyDictionary[wordLowerCaps] = 1;
}
}
}
wordFrequencyDictionary = (from entry in wordFrequencyDictionary orderby entry.Value descending select entry).ToDictionary(pair => pair.Key, pair => pair.Value);
}Even though we have quite a lot of code in this function, the idea is simple. Create a dictionary that will contain the frequency occurrence for each word in the article.
So for each article we load the text. Then we tokenize it (split it in words). For each word we check our article dictionary if the word is already present. If it is not – add it but if the word is contained just increment the counter. This will allow us to see how many times a word is appearing in the article.
Stopwords
Stopwords are very common words that appear in our article database. Words like “we”, “are” probably do not help at all in NLP tasks such as sentiment analysis or text classifications. Hence, we can remove stopwords to save computing time and efforts in processing large volumes of text.
The project contains a separate window that allows you to clean the stopwords manually.
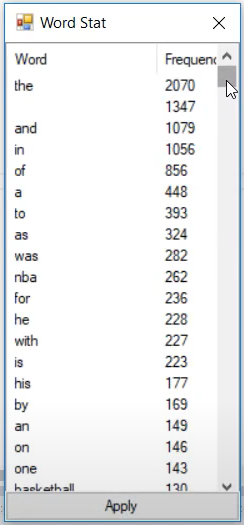
In this window here you can see the frequency of the words appearing in the articles. Naturally word separator ” ” (empty space), word connectors such as: “the”, “and”, “in”, “of”, “a” are one of the most used words in the articles.
But these words do not carry any valuable information to our article classification task. So it is good idea to remove them.
Article Classification with K-Means
Finally we are at the point where we can use K-Means to classify the articles.
Up until now we were creating a “Bag Of Words” dictionary which will help us vectorize and prepare the articles for K-Means like so:
foreach(TrainItem item in trainingDataSet)
{
Dictionary<string, int> localFrequency = new Dictionary<string, int>();
string[] words = item.Text.Split(' ');
foreach(string word in words)
{
string lowerWord = word.ToLower();
if (!localFrequency.ContainsKey(lowerWord))
localFrequency[lowerWord] = 1;
}
double[] inputVector = new double[wordFrequencyDictionary.Count];
foreach(KeyValuePair<string,int> pair in localFrequency)
{
if (wordFrequencyDictionary.ContainsKey(pair.Key))
{
int index = wordFrequencyDictionary.Keys.ToList().IndexOf(pair.Key);
inputVector[index] = pair.Value;
}
}
trainingDataSet[itemIndex].InputVector = inputVector;
itemIndex++;
}In this code “TrainingDataSet” represents the articles. “TrainingItem” represents only one article from the dataset. First we tokenize and normalize the article and create a local word frequency dictionary. We are creating the K-Means input vector from the “Bag Of Words” dictionary. If that dictionary contains the local word, we get the word index/position. On that position/index of the input vector we assign the local frequency value. That is how we create the input vector for K-Means algorithm.
K-Means training and classification
We’ve already covered the topics of K-Means training and classification in other posts.
So all we need to do now is choose the “K” or the number of clusters for our article dataset. In order to choose the appropriate value you can use the “Elbow Method” or your own intuition.
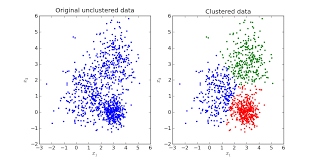
The image on the left would represent our original unclustered data. The end result should split the data into 3 clusters. One cluster for NBA related articles, other cluster for music and one cluster for company/business related articles.
The intuition behind this plot is that articles with similar content (for example NBA related articles) will have high occurrence of words related to the game of basketball, thus they will fall near each other.
Articles related to music will have words related to singers, bands and music. It is not expected a music article to contain high frequency of NBA and basketball related words. This notion will help K-Means split the data into appropriate clusters.
Bryan
March 27, 2021 at 6:13 pmwhere do i get the source code please
vanco
March 27, 2021 at 6:29 pmIt is right underneath the embedded video.
You can also download it from here: http://code-ai.mk/wp-content/uploads/2019/05/Article-Classification-KMeans-reupload.zip